Fitting simple models#
In this chapter we will focus on how to compute the measures of central tendency and variability that were covered in the previous chapter. Most of these can be computed using a built-in Python function, but we will show how to do them manually in order to give some intuition about how they work. First let’s load the NHANES data that we will use for our examples.
! pip install nhanes
from nhanes.load import load_NHANES_data
nhanes_data = load_NHANES_data()
adult_nhanes_data = nhanes_data.query('AgeInYearsAtScreening > 17')
Requirement already satisfied: nhanes in /miniconda/lib/python3.12/site-packages (0.5.1)
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
Since we will be analyzing the StandingHeightCm variable, we should exclude any observations that are missing this measurement. We will also recode the variable to be called Height in order to simplify the coding later.
adult_nhanes_data = adult_nhanes_data.dropna(subset=['StandingHeightCm']).rename(columns={'StandingHeightCm': 'Height'})
Mean#
The mean is defined as the sum of values divided by the number of values being summed:
$\(
\bar{X} = \frac{\sum_{i=1}^{n}x_i}{n}
\)$
Let’s say that we want to obtain the mean height for adults in the NHANES database (contained in the data Height that we generated above). We would sum the individual heights (using the .sum() operator) and then divide by the number of values:
adult_nhanes_data['Height'].sum() / adult_nhanes_data['Height'].shape[0]
166.3623438648053
There is, of course, a built-in operator for the data frame called .mean() that will compute the mean.
mean = adult_nhanes_data['Height'].mean()
We can now see what is the sum of squared error (SSE) of all weight values from the mean we calculated.
import numpy as np
SSE_mean = np.sum((adult_nhanes_data['Height'] - mean)**2)
print(SSE_mean)
551603.540492285
Now what happens if we choose a different number to represent the central tendency of the data? For example, how about we use mean+0.1?
Try a few different numbers, what do you find?
SSE_new = np.sum((adult_nhanes_data['Height'] - (mean + 0.1) )**2)
print(SSE_new)
551657.9804922851
Median#
The median is the middle value after sorting the entire set of values. First we sort the data in order of their values:
height_sorted = adult_nhanes_data['Height'].sort_values()
Next we find the median value. If there is an odd number of values in the list, then this is just the value in the middle, whereas if the number of values is even then we take the average of the two middle values. We can determine whether the number of items is even by dividing the length by two and seeing if there is a remainder; we do this using the %% operator, which is known as the modulus and returns the remainder:
height_length_mod_2 = height_sorted.shape[0] % 2
Here we will test whether the remainder is equal to one; if it is, then we will take the middle value, otherwise we will take the average of the two middle values. We can do this using an if/else structure, which executes different processes depending on which of the arguments are true. Here is a simple example:
if 1 > 2:
print('1 > 2')
else:
print('1 is not greater than two!')
1 is not greater than two!
For our example, we can use an if statement to determine how to compute the median, depending on whether there is an odd or even number of data points.
import numpy as np
if height_length_mod_2 == 1:
# odd number values - take the single midpoint
midpoint = int(np.floor(height_sorted.shape[0] / 2))
median = height_sorted[midpoint]
else:
# even number of values - need to average the two middle points
midpoints = [int((height_sorted.shape[0] / 2) - 1),
int(height_sorted.shape[0] / 2)]
median = height_sorted.iloc[midpoints].mean()
There is a lot going on there, so let’s unpack it. The first line of the if statement asks whether the remainder is equal to one — if so, then it executes the lines that are indented below it. Python uses indentation as part of its syntax, so you always need to be very careful about indentation. If the remainder is one, that means that the number of observations is odd, and thus that we can simply take the single middle point. We determine this by dividing the number of observations by two, and then rounding up (which is what the np.floor() function does, it looks for the integer just below a value. We choose the one below because all indices start from 0). Finally, we have to convert this number into an integer using the int() function, since we can only use integers to index a data frame.
If the first test is false — that is, if the remainder is zero — then, the second section of code (after the else statement) will be executed instead. Here we need to find the two midpoints and average them, so we create a new list containing those two points, and then use that index our data and then take the mean.
Mode#
The mode is the most frequent value that occurs in a variable. For example, let’s say that we had the following data:
import pandas as pd
toy_data = pd.DataFrame({'myvar': ['a', 'a', 'b', 'c']})
We can see by eye that the mode is “a” since it occurs more often than the others. To find it computationally, let’s use the .value_counts() operator to find the frequency of each value:
myvar_frequencies = toy_data['myvar'].value_counts()
myvar_frequencies
myvar
a 2
b 1
c 1
Name: count, dtype: int64
Now let’s find the highest frequency, using the .max() operator:
max_frequency = myvar_frequencies.max()
max_frequency
2
Now we can find the values that have the maximum frequency:
mode = myvar_frequencies.loc[myvar_frequencies == max_frequency].index.values
Creating functions#
It is often useful to create our own custom function in order to perform a particular action. Let’s do that for our mode function:
def my_mode_function(input):
"""
A function to compute the mode.
Inputs:
------
input: a pandas Series
Outputs:
--------
mode: an array containing the mode values
"""
# make sure the input is a pandas series
input = pd.Series(input)
# compute the frequency distribution
frequencies = input.value_counts()
# compute the maximum frequency
max_frequency = frequencies.max()
# find the values matching the maximum frequency (i.e. the mode)
mode = frequencies.loc[
frequencies == max_frequency].index.values
return(mode)
Let’s look at this one section at a time.
The first row tells Python to define a new function, called “my_mode_function”, which takes in a single variable that will be called “input”. This variable only exists inside the function; you can’t access it from the outside.
The next section, surrounded by triple-quotes, is known as a docstring, and it provides documentation about our function. It’s always a good idea to write a docstring that describes what the function does, what kinds of inputs it expects, and what kind of output it produces.
The next line converts the input to a particular kind of variable called a pandas Series; this is the same kind of variable as a column in a data frame. Including this command allows our function to take in various types of variables (including Series and lists) and treat them as if they were a Series, using the operators that are available such as .value_counts().
The remaining lines perform the computations that we performed above to compute the mean.
The final line tells Python to return the value of the mode when the function is called. Let’s see this in action:
my_mode_function(['a', 'a', 'b', 'c'])
array(['a'], dtype=object)
Let’s also make sure that it works properly if there are multiple modes:
my_mode_function(['a', 'a', 'b', 'c', 'c'])
array(['a', 'c'], dtype=object)
Variability#
Let’s first compute the variance, which is the average squared difference between each value and the mean. Let’s do this with our cleaned-up version of the height data, but instead of working with the entire dataset, let’s take a random sample of 150 individuals:
sample_size = 150
height_sample = adult_nhanes_data.sample(sample_size)['Height']
We could have simply entered the number 150 into the sample function, but by first creating a new variable called sample_size and setting it to 150, we make it clearer to the reader of the code exactly what this number refers to. It’s always good practice to create a new variable rather than typing a number directly into a formula.
To compute the variance we need we need to first compute the sum of squared errors from the mean. In Python, we can square a vector using **2:
sum_of_squared_errors = np.sum((height_sample - height_sample.mean())**2)
Then we divide by N - 1 to get the estimated variance:
variance_estimate = sum_of_squared_errors / (height_sample.shape[0] - 1)
variance_estimate
87.97215033557045
We can compare this to the built-in .var() operator:
height_sample.var()
87.97215033557045
We can get the standard deviation by simply taking the square root of the variance:
std_dev_estimate = np.sqrt(variance_estimate)
std_dev_estimate
9.379347010083935
Which is the same value obtained using the built-in .std() operator:
height_sample.std()
9.379347010083935
Z-scores#
A Z-score is obtained by first subtracting the mean and then dividing by the standard deviation of a distribution. Let’s do this for the height_sample data.
mean_height = height_sample.mean()
sd_height = height_sample.std()
z_height = (height_sample - mean_height) / sd_height
Now let’s plot the histogram of Z-scores alongside the histogram for the original values. Matplotlib allows us to create a grid of figures using the plt.subplot() function. Let’s see this in action:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.hist(height_sample)
plt.subplot(1, 2, 2)
plt.hist(z_height)
(array([ 5., 8., 23., 28., 25., 24., 16., 8., 6., 7.]),
array([-2.17413856, -1.70928744, -1.24443631, -0.77958519, -0.31473406,
0.15011706, 0.61496818, 1.07981931, 1.54467043, 2.00952156,
2.47437268]),
<BarContainer object of 10 artists>)
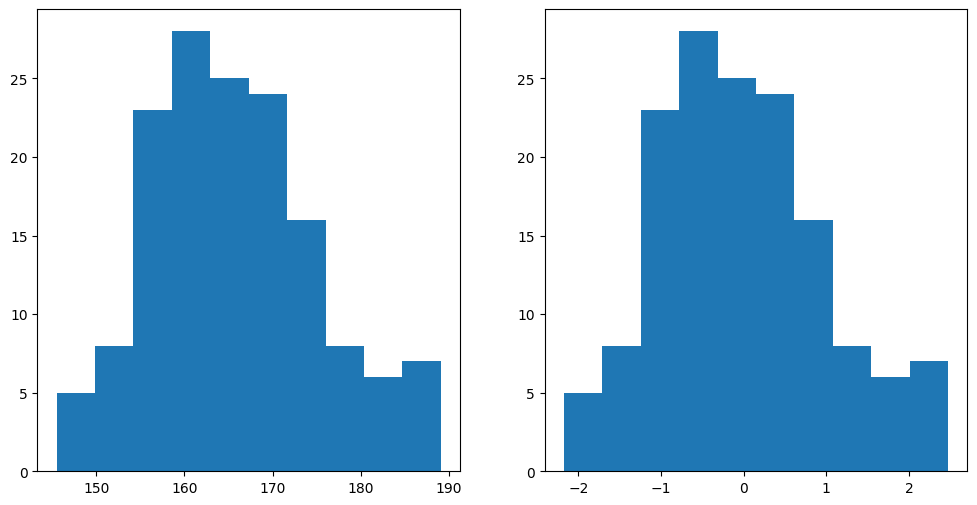
You will notice that the shapes of the histograms are exactly the same. We can also see this by plotting the two variables against one another in a scatterplot:
plt.scatter(height_sample, z_height)
<matplotlib.collections.PathCollection at 0x7f3c781158e0>
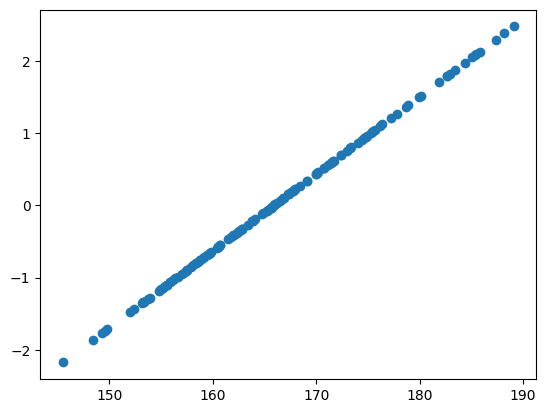
You see here that they fall along a straight line, meaning that they are perfectly related to each other exactly — the only difference is where they are located on the number line.