Capitulo 17 Hacer investigación reproducible
La mayoría de la gente piensa que la ciencia es una manera confiable de contestar preguntas acerca del mundo. Cuando nuestro médico prescribe un tratamiento confiamos en que el tratamiento ha demostrado efecto a través de investigación, y tenemos una fe similar en que los aviones sobre los que volamos no se van a caer desde el cielo. Sin embargo, desde 2005 ha habido una creciente preocupación de que la ciencia podría no siempre trabajar tan bien como pensábamos que lo hacía. En este capítulo discutiremos estas preocupaciones acerca de la reproducibilidad de la investigación científica, y esbozaremos los pasos que uno podría tomar para asegurarse que nuestros resultados estadísticos sean tan reproducibles como sea posible.
17.1 Cómo pensamos que funciona la ciencia
Digamos que estamos interesados en un proyecto de investigación sobre cómo los niños escogen lo que comen. Esta es una pregunta que fue realizada por un estudio de un investigador muy conocido en temas de hábitos alimenticios, Brian Wansink, y sus colegas en 2012. La visión estándar (y, como veremos, algo ingenua) propone algo como esto:
- Comienzas con una hipótesis.
- Etiquetar comidas con personajes populares deberían causar que lxs niñxs elijan comidas “saludables” más frecuentemente.
- Recolectas algunos datos.
- Ofreces a niñxs la decisión de comer entre una galleta o una manzana, etiquetados ya sea con un Elmo o con una etiqueta control, y registras lo que eligieron.
- Realizas análisis estadísticos para probar la hipótesis nula.
- “La comparación preplaneada muestra que las manzanas etiquetadas con Elmo se asociacion con un incremento en la selección de los niños por sobre una galleta, de 20.7% a 33.8% (\(\chi^2\)=5.158; P=.02)” (Wansink, Just, and Payne 2012).
- Llegas a una conclusión basado en los datos.
- “Este estudio sugiere que el uso de etiquetados con personajes atractivos puede beneficiar comidas salubles más de lo que beneficiarían comidas más indulgentes y altamente procesadas. Así como nombres atractivos han mostrado incrementar la selección de comidas saludables en cafeterías escolares, marcas y personajes de caricaturas podrían hacer lo mismo con niños pequeños” (Wansink, Just, and Payne 2012).
17.2 Cómo funciona (a veces) realmente la ciencia
Brian Wansink es muy reconocido por sus libros sobre “Mindless Eating,” y sus honorarios por dar charlas corporativas en algún momento estuvieron en las decenas de miles de dólares. En 2017, un grupo de investigadores comenzó a examinar algunos de sus investigaciones publicadas, comenzando por un conjunto de artículos acerca de cuánta pizza come la gente en un buffet. Los investigadores pidieron a Wansink que compartiera sus datos de esos estudios pero él se rehusó, por lo que excavaron en sus artículos publicados y encontraron un gran número de inconsistencias y problemas estadísticos. La publicidad alrededor de este análisis llevó a un número de otros investigadores a examinar el pasado de Wansink, incluyendo el obtener emails entre Wansink y sus colaboradores. Como reportó Stephani Lee en Buzzfeed, estos emails mostraron justo qué tan lejos estaban las prácticas reales de investigación de Wansink del modelo ingenuo de hacer ciencia:
…en septiembre de 2008, cuando Payne estaba revisando los datos después de haber sido recolectados, él no encontró una fuerte relación entre manzanas-y-Elmo - al menos aún no. … “He adjuntado en este mensaje unos resultados iniciales del estudio de niños para tu reporte,” escribió Payne a sus colaboradores. “No se desanimen. Parece que las etiquetas en las frutas podrían funcionar (con un poco más de magia).” … Wansink también reconoció que el artículo era débil mientras lo preparaba para enviar a las revistas. El valor p era de 0.06, sólo un poco por arriba del estándar de oro del punto de corte de 0.05. Era un “escollo,” como lo mencionó en un email el 7 de enero de 2012. … “Me parece que debería ser más bajo,” escribió, adjuntando un borrador. “Quieren darle un vistazo y ver qué piensan. Si pueden tener los datos, y necesitan algunos ajustes, sería bueno lograr que ese valor sea menor que .05.” … Después, en 2012, el estudio apareció en la prestigiosa revista JAMA Pediatrics, con el valor p de 0.06 intacto. Pero en septiembre de 2017, fue retractado y reemplazado con una versión que reporta un valor p de 0.02. Y un mes después, fue retractado de nuevo por una razón completamente diferente: Wansink admitió que el experimento no había sido realizado con niños de 8 a 11 años, como originalmente habían reportado, sino con preescolares.
Este tipo de comportamientos finalmente atrapó a Wansink; quince de sus estudios publicados han sido retractados y en 2018 renunció a su cargo como profesor en Cornell University.
17.3 La crisis de reproducibilidad en la ciencia
Mientras que pensamos que el tipo de comportamiento fraudulento visto en el caso de Wansink es relativamente raro, se ha vuelto crecientemente claro que los problemas con la reproducibilidad son mucho más generalizados en la ciencia de lo que se pensaba. Esto se volvió particularmente evidente en 2015, cuando un grupo grande de investigadores publicó un estudio en la revista Science titulado “Estimating the reproducibility of psychological science”(Open Science Collaboration 2015). En este artículo, los investigadores tomaron 100 estudios publicados en psicología e intentaron reproducir los resultados originalmente reportados en los artículos. Sus hallazgos fueron desconcertantes: Mientras que 97% de los artículos originales había reportado resultados estadísticamente significativos, sólo 37% de estos efectos fueron estadísticamente significativos en el estudio de replicación. Aunque estos problemas en psicología han recibido una gran atención, parecen estar presentes en casi todas las áreas de la ciencia, desde biología de cáncer (Errington et al. 2014) y química (Baker 2017) hasta economía (Christensen and Miguel 2016) y ciencias sociales (Camerer et al. 2018).
La crisis de reproducibilidad que emergió después de 2010 fue realmente predicha por John Ioannidis, un médico de Stanford quien escribió un artículo en 2005 titulado “Why most published research findings are false”(Ioannidis 2005). En este artículo, Ioannidis argumentó que el uso de la prueba estadística de hipótesis nula en el contexto de la ciencia moderna necesariamente llevaría a altos niveles de resultados falsos.
17.3.1 Valor predictivo positivo y significatividad estadística
El análisis de Ioannidis se enfocó en un concepto conocido como el valor predictivo positivo (positive predictive value, PPV), que es definido como la proporción de resultados positivos (que generalmente se traducen como “hallazgos estadísticamente significativos”) que son verdaderos:
\[ PPV = \frac{p(true\ positive\ result)}{p(true\ positive\ result) + p(false\ positive\ result)} \] Asumiendo que conocemos la probabilidad de que nuestra hipótesis sea verdadera (\(p(hIsTrue)\)), entonces la probabilidad de un resultado positivo verdadero es simplemente \(p(hIsTrue)\) multiplicado por el poder estadístico del estudio:
\[ p(true\ positive\ result) = p(hIsTrue) * (1 - \beta) \] donde \(\beta\) es la tasa de falsos negativos. La probabilidad de un resultado falso positivo está determinada por \(p(hIsTrue)\) y la tasa de falsos positivos \(\alpha\):
\[ p(false\ positive\ result) = (1 - p(hIsTrue)) * \alpha \]
PPV entonces se define como:
\[ PPV = \frac{p(hIsTrue) * (1 - \beta)}{p(hIsTrue) * (1 - \beta) + (1 - p(hIsTrue)) * \alpha} \]
Primero veamos un ejemplo donde la probabilidad de que nuestra hipótesis sea verdadera es alta, digamos 0.8 - aunque nota que en general no podemos saber realmente esta probabilidad. Digamos que realizamos un estudio con los valores estándar de \(\alpha=0.05\) y \(\beta=0.2\). Podemos calcular el PPV como:
\[ PPV = \frac{0.8 * (1 - 0.2)}{0.8 * (1 - 0.2) + (1 - 0.8) * 0.05} = 0.98 \] Esto significa que si encontramos un resultado positivo en un estudio donde la hipótesis es probable que sea verdadera y el poder es alto, entonces la probabilidad de acertar es alto. Nota, sin embargo, que un campo de investigación donde las hipótesis tienen tan alta probabilidad de ser verdaderas no es probablemente un campo de estudio muy interesante; ¡la investigación es más importante cuando nos dice algo inesperado!
Hagamos este mismo análisis para un campo donde \(p(hIsTrue)=0.1\) – esto es, la mayoría de las hipótesis siendo probadas son falsas. En este caso, PPV es:
\[ PPV = \frac{0.1 * (1 - 0.2)}{0.1 * (1 - 0.2) + (1 - 0.1) * 0.05} = 0.307 \]
Esto significa que en un campo donde la mayoría de las hipótesis son probablemente erróneas (esto es, un campo científico interesante donde los investigadores están probando hipótesis arriesgadas), ¡incluso cuando encontramos un resultado positivo es más probable estar equivocados que en lo correcto! De hecho, este es sólo otro ejemplo del efecto de tasa base que discutimos en el contexto de la prueba de hipótesis – cuando un resultado es improbable, entonces es casi seguro que la mayoría de los resultados positivos serán falsos positivos.
Podemos simular esto mostrando cómo el PPV se relaciona con el poder estadístico, como una función de la probabilidad previa (prior probability) de que la hipótesis sea cierta/verdadera (ve la Figura 17.1).
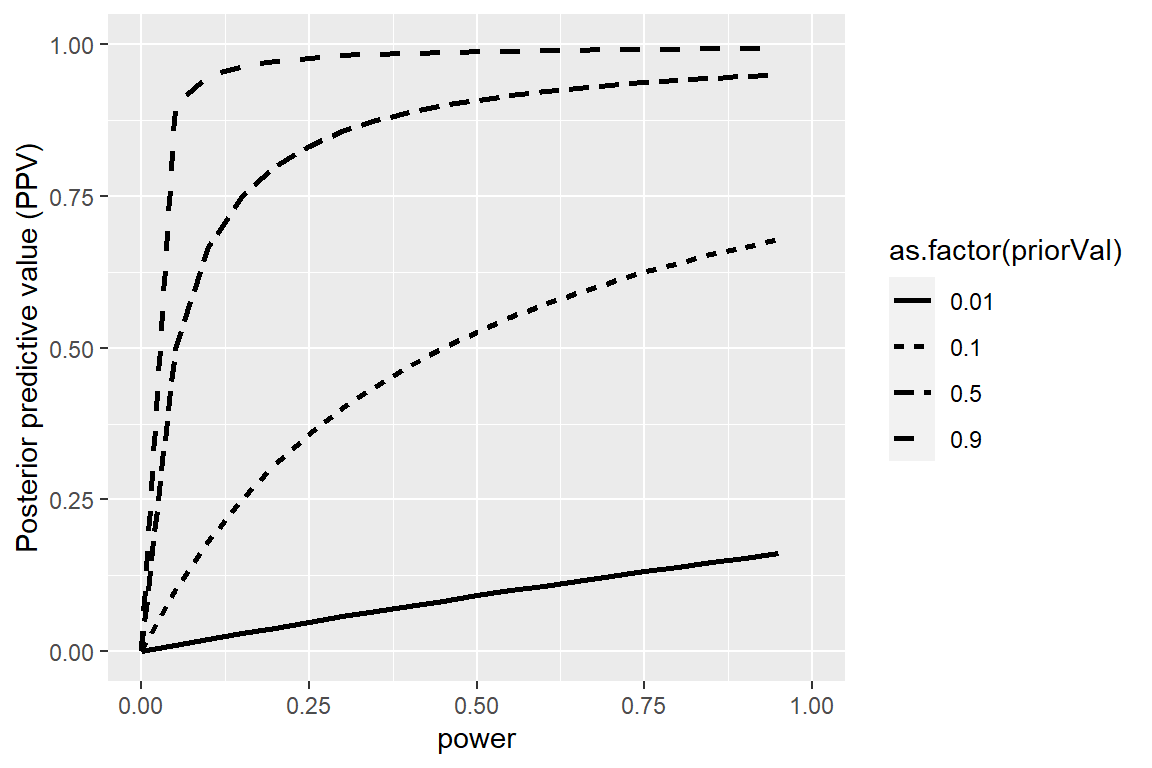
Figura 17.1: Una simulación del valor predictivo posterior como una función del poder estadístico (graficado en el eje X) y la probabilidad previa de que la hipótesis sea cierta (graficada como líneas separadas).
Desafortunadamente, el poder estadístico se mantiene bajo en muchas áreas de la ciencia (Smaldino and McElreath 2016), sugiriendo que muchos hallazgos científicos reportados son falsos.
Un ejemplo entretenido de esto se vio en un artículo de Jonathan Schoenfeld y John Ioannidis, titulado “Is everything we eat associated with cancer? A systematic cookbook review”(Schoenfeld and Ioannidis 2013). Ellos examinaron un gran número de artículos que habían evaluado la relación entre diferentes comidas y el riesgo de desarrollar cáncer, y encontraron que 80% de los ingredientes habían sido asociados con un incremento o un decremento del riesgo de desarrollar cáncer. En la mayoría de los casos, la evidencia estadística era débil, y cuando los resultados eran combinados entre estudios, el resultado era nulo.
17.3.2 La maldición del ganador
Otro tipo de error puede ocurrir cuando el poder estadístico es bajo: Nuestras estimaciones del tamaño del efecto estarán infladas. A este fenómeno frecuentemente se le conoce como la “maldición del ganador” (“winner’s curse”), que viene de la economía, donde se refiere al hecho de que en ciertos tipos de subastas (donde el valor es el mismo para todos, como un jarrón con monedas, y donde las ofertas son privadas), está garantizado que el ganador pagará más de lo que vale lo subastado. En ciencia, la maldición del ganador se refiere al hecho de que el tamaño del efecto estimado de un resultado significativo (i.e. un ganador) es casi siempre una sobreestimación del verdadero tamaño del efecto.
Podemos simular esto para poder ver cómo es que el tamaño del efecto estimado para resultados significativos está relacionado con el tamaño del efecto verdadero subyacente. Generemos datos para los cuales haya un tamaño de efecto verdadero de d = 0.2, y estimemos el tamaño del efecto para aquellos resultados donde haya un efecto significativo detectado. La figura izquierda de la Figura 17.2 muestra que cuando el poder es bajo, el tamaño de efecto estimado para resultados significativos puede estar altamente inflado comparado con el verdadero tamaño de efecto.
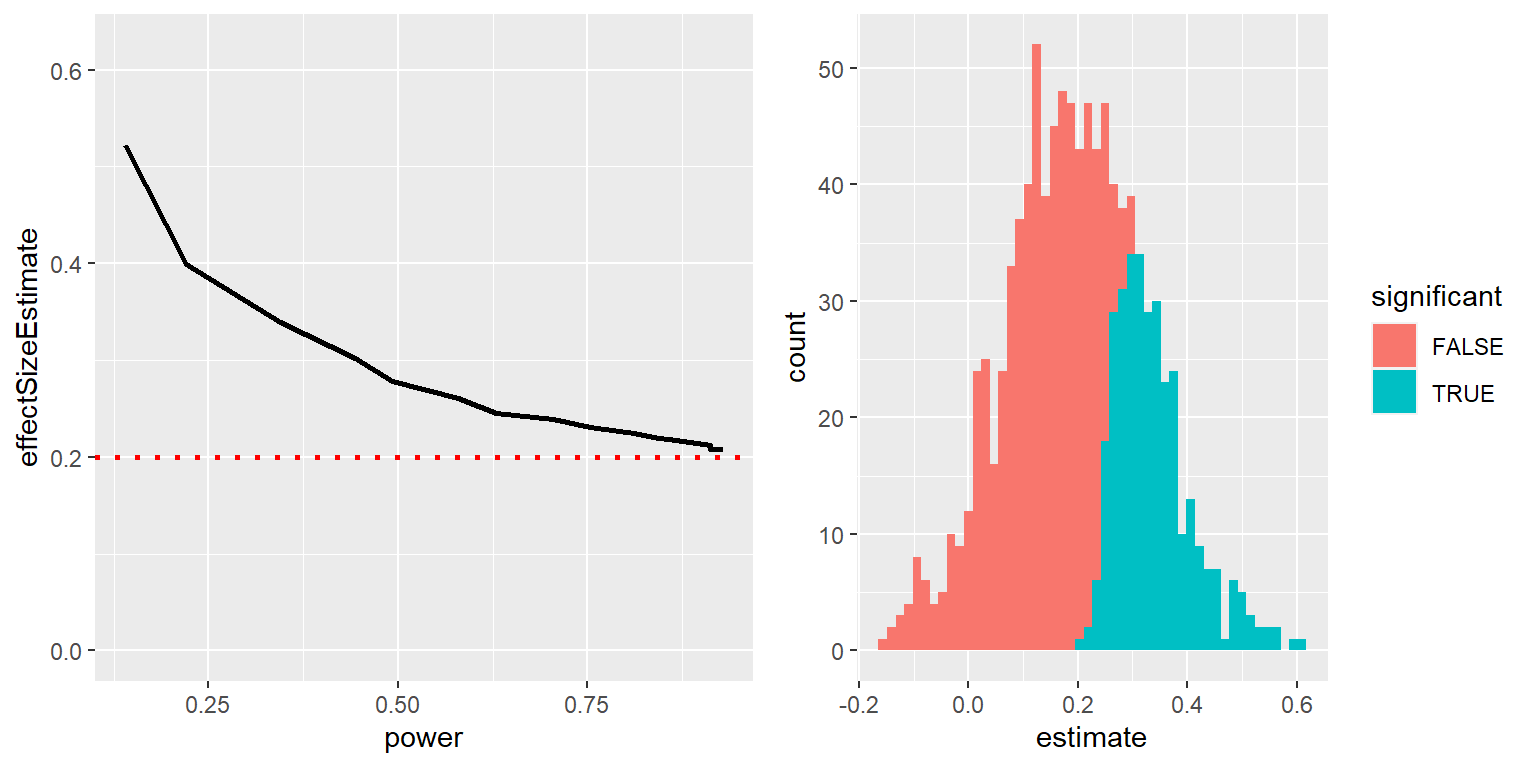
Figura 17.2: Izquierda: Una simulación de la maldición del ganador como función del poder estadístico (eje x). La línea sólida muestra el tamaño de efecto estimado, y la línea punteada muestra el tamaño de efecto real. Derecha: Un histograma mostrando los tamaños de efecto para un conjunto de muestras de una base de datos, con resultados significativos en azul y los no significativos en rojo.
Podemos revisar una sola simulación para poder ver por qué sucede esto. En el panel derecho de la Figura 17.2, puedes ver un histograma de los tamaños de efecto estimados para 1000 muestras, separados según si la prueba estadística resultó estadísticamente significativa. Debería ser claro a partir de esta figura que si estimamos un tamaño de efecto sólo basándonos en resultados significativos, entonces nuestra estimación estará inflada; sólo cuando la mayoría de los resultados sean significativos (i.e. el poder es alto y el efecto es relativamente grande) será que nuestra estimación se acercará al tamaño de efecto real.
17.4 Prácticas cuestionables de investigación
Un libro popular titulado “The Compleat Academic: A Career Guide,” publicado por la American Psychological Association (Darley, Zanna, and Roediger 2004), busca proveer a los aspirantes a investigadores con una guía sobre cómo construir una carrera. En un capítulo escrito por un reconocido psicólogo social, Daryl Bem, titulado “Writing the Empirical Journal Article,” Bem provee de sugerencias sobre cómo escribir un artículo de investigación. Desafortunadamente, las prácticas que él sugiere son profundamente problemáticas, y se han convertido en lo que conocemos como prácticas cuestionables de investigación (questionable research practices, QRPs).
¿Cuál artículo deberías escribir? Existen dos posibles artículos que puedes escribir: (1) el artículo que planeaste escribir cuando diseñaste tu estudio, o (2) el artículo que hace más sentido ahora que has visto tus resultados. Raramente son los mismos, y la respuesta correcta es el (2).
Lo que Bem sugiere aquí es conocido como HARKing (del inglés Hypothesizing After the Results are Known)(Kerr 1998). Esto podría parecer inocuo, pero es problemático porque permite que el investigador re-encuadre una conclusión post-hoc (que deberíamos tomar con un grano de sal) como si hubiera sido una predicción a priori (en las cuales tendríamos mayor confianza). En esencia, permite al investigador reescribir su teoría basada en los hechos, en lugar de usar su teoría para hacer predicciones y luego probarlas – parecido a mover la portería en dirección de donde fue la pelota. Por lo tanto se hace muy difícil corregir ideas incorrectas, pues la portería siempre podría moverse para que se acomode a los datos. Bem continúa:
Analizar datos Examínalos desde todos los ángulos. Analiza los sexos de manera separada. Elabora nuevos índices compuestos. Si un dato sugiere una nueva hipótesis, trata de encontrar evidencia adicional en algún otro lado entre los datos. Si ves trazos débiles de patrones interesantes, trata de reorganizar los datos para que tengan un relieve más marcado. Si hay participantes que no te gusten, o ensayos, observadores, o entrevistadores que te hayan dado resultados anómalos, descártalos (temporalmente). Lánzate a una expedición de pesca para algo - cualquier cosa - interesante. No, esto no es inmoral.
Lo que Bem sugiere es conocido como p-hacking, que se refiere a intentar muchos diferentes análisis hasta que uno encuentre uno con un resultado significativo. Bem está en lo correcto de que si uno reporta todos los análisis realizados en los datos entonces esta estrategia no sería “inmoral.” Sin embargo, es raro ver un artículo discutir todos los análisis que fueron realizados en los datos; en su lugar, los artículos frecuentemente sólo presentan los análisis que funcionaron - lo que usualmente significa que encontraron un resultado estadísticamente significativo. Hay muchas maneras en que uno podría hacer p-hacking:
- Analizar los datos después de cada participante, y detener la recolección de datos una vez que alcanzaste p<.05.
- Analizar muchas variables diferentes, pero sólo reportar aquellas con p<.05.
- Recolectar muchas condiciones experimentales diferentes, pero sólo reportar aquellas con p<.05.
- Excluir participantes para obtener p<.05.
- Transformar los datos para obtener p<.05.
Un artículo muy conocido escrito por Simmons, Nelson, and Simonsohn (2011) mostró que el uso de este tipo de estrategias de p-hacking puede incrementar en gran medida la tasa real de falsos positivos, resultando en un mayor número de resultados positivos falsos.
17.4.1 ¿ESP o QRP?
En 2011, el mismo Daryl Bem publicó un artículo (Bem 2011) que afirmó haber encontrado evidencia científica de percepción extrasensorial (extrasensory perception, ESP). El artículo afirma:
Este artículo reporta 9 experimentos, involucrando más de 1,000 participantes, que prueban la influencia retroactiva al “invertir en el tiempo” efectos psicológicos bien estudiados de manera que las respuestas individuales fueron obtenidas antes de que ocurrieran los eventos putativamente causales. …El tamaño de efecto promedio (d) en el rendimiento psi en todos los 9 experimentos fue de 0.22, y todos excepto uno de los experimentos obtuvieron resultados estadísticamente significativos.
Conforme los investigadores comenzaron a analizar el artículo de Bem, se fue volviendo claro que él había aplicado todas las prácticas cuestionables de investigación (QRPs) que él mismo había recomendado en el capítulo mencionado arriba. Como mencionó Tal Yarkoni en un blog que examinó el artículo de Bem:
- Los tamaños de muestra variaron entre los estudios.
- Diferentes estudios parecen haberse agrupado o separado en partes.
- Los estudios permiten muchas diferentes hipótesis, y no queda claro cuáles fueron planeadas por adelantado.
- Bem usó pruebas de una sola cola incluso cuando no queda claro que hubiera una predicción direccional (así que el alfa es realmente de 0.1).
- La mayoría de los valores p están muy cerca de 0.05.
- No queda claro cuántos otros estudios se realizaron pero no fueron reportados.
17.5 Hacer investigación reproducible
En los años que han pasado desde que surgió la crisis de reproducibilidad, ha habido un movimiento robusto para desarrollar herramientas que ayuden a proteger la reproducibilidad de la investigación científica.
17.5.1 Pre-registro
Una de las ideas que ha ganado mayor apoyo es el pre-registro, en el cual uno envía una descripción detallada de un estudio (incluyendo todos los análisis de datos) a un repositorio confiable (como el del Open Science Framework o AsPredicted.org). Al especificar los propios planes en detalle antes de analizar los datos, el pre-registro provee mayor confianza de que los análisis no sufrieron de p-hacking o de otras prácticas cuestionables de investigación.
Los efectos del pre-registro en los ensayos clínicos en medicina han sido impactantes. En el 2000, el National Heart, Lung, and Blood Institute (NHLBI) comenzó requiriendo que todos los ensayos clínicos fueran pre-registrados usando el sistema en ClinicalTrials.gov. Esto provee de un experimento natural para observar los efectos del pre-registro de estudios. Cuando Kaplan and Irvin (2015) examinaron resultados de ensayos clínicos a lo largo del tiempo, encontraron que el número de resultados positivos en los ensayos clínicos se redujo grandemente después del año 2000 comparado con estudios de años previos. Aunque hay muchas posibles causas, parece probable que, previo al requisito de pre-registrar, los investigadores podían cambiar sus métodos o hipótesis para poder obtener un resultado positivo, lo que se volvió más difícil de hacer después de que fuera requerido el pre-registro.
17.5.2 Prácticas reproducibles
El artículo de Simmons, Nelson, and Simonsohn (2011) presentó un conjunto de prácticas sugeridas para hacer la investigación más reproducible, todas ellas deberían convertirse en un estándar para los investigadores:
- Los autores deben decidir la regla con la cual se dará por terminada la recolección de datos antes de comenzar a recolectar datos y reportar esta regla en su artículo.
- Los autores deben recolectar por lo menos 20 observaciones por celda o en su lugar proveer de una justificación convincente del costo de la recolección de datos.
- Los autores deben enlistar todas las variables recolectadas en un estudio.
- Los autores deben reportar todas las condiciones experimentales, incluyendo las manipulaciones que hayan fallado.
- Si se eliminaron observaciones, los autores deben también reportar cómo son los resultados estadísticos si las observaciones se incluyeran.
- Si un análisis incluye una covariable, los autores deben reportar los resultados estadísticos del análisis sin la covariable.
17.5.3 Replicación
Uno de los sellos distintivos de la ciencia es la idea de replicación (replication) – esto es, otros investigadores deben ser capaces de realizar el mismo estudio y obtener el mismo resultado. Desafortunadamente, como vimos en el resultado del Replication Project discutido previamente, muchos hallazgos no han sido replicables. La mejor manera de asegurar la replicabilidad de nuestra investigación es primero replicarla por nuestra cuenta; para algunos estudios esto simplemente no será posible, pero siempre que sea posible uno debería asegurarse de que nuestros hallazgos se sostengan al estudiar una nueva muestra. Esa nueva muestra debería tener suficiente poder estadístico para encontrar el tamaño de efecto de interés; en muchos casos, esto requerirá una muestra más grande que la del estudio original.
Es importante tener en mente un par de cosas con respecto a la replicación. Primero, el hecho de que si un intento de replicación falla no necesariamente significa que el hallazgo original era falso; recuerda que un poder de nivel estándar de 80%, aún hay una probabilidad de uno de cinco de que el resultado sea no significativo, incluso si existe un efecto verdadero. Por esta razón, generalmente queremos ver múltiples replicaciones de cualquier hallazgo importante antes de decidir si creeremos o no en él. Desafortunadamente, muchas áreas de estudio, incluyendo la psicología, han fallado en seguir este consejo en el pasado, llevando a que haya hallazgos de “libro de texto” que probablemente sean falsos. Con respecto a los estudios de ESP de Daryl Bem, un intento de replicación grande involucrando 7 estudios falló en replicar sus hallazgos (Galak et al. 2012).
Segundo, recuerda que el valor p no nos provee de una medida de la probabilidad de que un hallazgo se replique. Como discutimos previamente, el valor p es un enunciado acerca de la probabilidad de nuestros datos bajo una hipótesis nula específica; no nos dice nada acerca de la probabilidad de que un hallazgo sea realmente verdadero (como aprendimos en el capítulo sobre análisis Bayesiano). Para poder conocer la probabilidad de replicación necesitamos conocer la probabilidad de que el hallazgo sea verdadero, y esto generalmente no lo sabemos.
17.6 Hacer análisis de datos reproducibles
Hasta el momento nos hemos enfocado en la habilidad de replicar los hallazgos de otros investigadores en nuevos experimentos, pero otro aspecto importante de la reproducibilidad es el ser capaces de reproducir el análisis de alguien en sus propios datos, a lo que llamamos reproducibilidad computacional (computational reproducibility). Esto requiere que lxs investigadores compartan tanto sus datos como su código de análisis, para que otrxs investigadores puedan tratar de reproducir los resultados así como potencialmente probar diferentes métodos de análisis sobre los mismos datos. Hay un movimiento creciente en psicología hacia compartir código y datos abiertamente (open sharing); por ejemplo, la revista Psychological Science ahora provee de insignias a los artículos que comparten materiales, datos, y código de la investigación, así como también para los pre-registros.
La habilidad para reproducir análisis es una razón por la que promovemos fuertemente el uso de análisis en código (como al usar R) en lugar de usar software gráfico, de “apuntar-y-dar-click.” También es una razón por la que promovemos el uso de software libre y de fuente abierta (open-source, como R) en oposición a software comercial, que requeriría que los demás compraran el software para poder reproducir cualquier análisis.
Existen muchas maneras de compartir tanto el código como los datos. Una manera común de compartir código es a través de sitios web que apoyen control de versiones en software, como lo hace Github. Pequeñas bases de datos también se pueden compartir a través de este mismo tipo de sitios; bases de datos más grandes pueden ser compartidas a través de portales para compartir datos como Zenodo, o a través de portales especializados para tipos específicos de datos (como OpenNeuro para datos de neuroimagen).
17.7 Conclusión: Hacer mejor ciencia
Es responsabilidad de cada científico el mejorar sus prácticas de investigación para poder incrementar la reproducibilidad de su investigación. Es esencial recordar que la meta de la investigación no es encontrar un resultado significativo; sino hacerse y responderse preguntas acerca de la naturaleza en la manera más honesta posible. La mayoría de nuestras hipótesis estarán equivocadas, y debemos estar cómodos con eso, para que cuando encontremos una que esté en lo correcto, estemos aún más seguros de su verdad.
17.8 Objetivos de aprendizaje
- Describir el concepto de p-hacking y sus efectos en la práctica científica.
- Describir el concepto de valor predictivo positivo y su relación con poder estadístico.
- Describir el concepto de pre-registro y cómo puede ayudar a proteger en contra de las prácticas cuestionables de investigación.
17.9 Lecturas sugeridas
- Rigor Mortis: How Sloppy Science Creates Worthless Cures, Crushes Hope, and Wastes Billions, por Richard Harris
- Improving your statistical inferences - un curso en línea sobre cómo realizar mejores análisis estadísticos, incluyendo muchos de los puntos que tocamos en este capítulo.