Capitulo 3 Resumir datos
Mencioné en la Introducción que uno de los grandes descubrimientos de la estadística es la idea de que podemos entender mejor el mundo si nos deshacemos de información, y eso es justo lo que hacemos cuando resumimos un cojunto de datos. En este Capítulo discutiremos por qué y cómo resumir datos.
3.1 ¿Por qué resumir datos?
Cuando resumimos datos, estamos necesariamente tirando información, y uno podría objetar esto plausiblemente. Como un ejemplo, regresemos al estudio PURE que discutimos en el Capítulo 1. ¿No deberíamos pensar que todos los detalles de cada individuo importan, más allá de los que se resumieron en el conjunto de datos? ¿Qué decir de los detalles específicos sobre cómo fue recolectada la información, como el momento del día o el estado de ánimo del participante? Todos esos detalles se pierden cuando resumimos los datos.
Una razón por la que resumimos datos es porque nos provee de una manera de generalizar - esto es, hacer enunciados generales que van más allá de observaciones específicas. La importancia de la generalización fue subrayada por el escritor Jorge Luis Borges en su cuento “Funes El Memorioso,” donde describe a un individuo que pierde la habilidad de olvidar. Borges se enfoca en la relación entre generalización (i.e. tirar datos) y el pensamiento: “Pensar es olvidar diferencias, es generalizar, abstraer. En el abarrotado mundo de Funes no había sino detalles, casi inmediatos.”
Les psicólogues han estudiado por largo tiempo todas las maneras en que la generalización es central al pensamiento. Un ejemplo es la categorización: somos capaces de reconocer fácilmente diferentes ejemplos de la categoría de “aves” a pesar de que los ejemplos individuales puedan ser muy diferentes en características superficiales (como un avestruz, un petirrojo, y una gallina). De manera importante, la generalización nos permite hacer predicciones acerca de estos individuos – en el caso de las aves, podemos predecir que vuelan y comen semillas, y que probablemente no puedan manejar un carro o hablar inglés. Estas predicciones no serán siempre correctas, pero frecuentemente serán suficientemente buenas para ser útiles en el mundo.
3.2 Resumir datos usando tablas
Una manera simple de resumir datos es el generar una tabla que represente el conteo de varios tipos de observaciones. Este tipo de tabla ha sido usado durante miles de años (ve la Figura 3.1).

Figura 3.1: Una tabla sumeria en el Louvre, que muestra un contrato de venta de una casa y un terreno. Dominio público, via Wikimedia Commons.
Veamos algunos ejemplos del uso de tablas, usando un conjunto de datos más realista. A lo largo de este libro usaremos la base de datos de la Encuesta Nacional de Nutrición y Salud (National Health and Nutrition Examination Survey, NHANES). Este es un estudio en curso que evalúa el status de salud y nutrición de una muestra de personas de los Estados Unidos en múltiples variables diferentes. Aquí usaremos una versión de la base de datos que está disponible para el paquete de software estadístico R. Para este ejemplo, miraremos una variable simple llamada “PhysActive” en la base de datos. Esta variable contiene uno de tres diferentes valores: “Sí” o “No” (indicando si la persona reportó o no el hacer “deportes moderados o de intensidad vigorosa, actividades de fitness o recreacionales”), o “NA” si el dato está perdido para esa persona. Existen varias razones por las cuales el dato podría estar perdido; por ejemplo, esta pregunta no se le realizó a menores a 12 años, mientras que en otros casos una persona adulta podría haber declinado el contestar la pregunta durante la entrevista, o el registro de la respuesta realizado por quien entrevistó podría resultar ilegible.
3.2.1 Distribuciones de frecuencias
Una distribución describe cómo los datos se dividen en diferentes valores posibles. Para este ejemplo, veamos cuántas personas caen en cada una de las categorías de actividad física.
| PhysActive | AbsoluteFrequency |
|---|---|
| No | 2473 |
| Yes | 2972 |
| NA | 1334 |
La tabla 3.1 muestra las frecuencias de cada uno de los diferentes valores; había 2473 personas que respondieron “No” a la pregunta, 2972 que respondieron “Sí,” y 1334 de quienes no hubo una respuesta. Llamamos a esto una distribución de frecuencias porque nos dice qué tan frecuente sucede en nuestra muestra cada uno de los valores posibles.
Esto nos muestra la frecuencia absoluta de cada una de los diferentes valores, para todas las personas que sí dieron una respuesta. De esta información, podemos ver que hubo más personas respondiendo “Sí” que “No,” pero puede ser difícil ver qué tan grande es la diferencia relativa sólo viendo estos números absolutos. Por esta razón, frecuentemente preferimos presentar los datos usando frecuencias relativas, que se obtienen dividiendo cada frecuencia entre la suma de todas las frecuencias absolutas:
\[ frecuencia\ relativa_i = \frac{frecuencia\ absoluta_i}{\sum_{j=1}^N frecuencia\ absoluta_j} \] La frecuencia relativa provee una manera mucho más fácil para observar qué tan grande es la diferencia. También podemos interpretar las frecuencias relativas como porcentajes si las multiplicamos por 100. En este ejemplo, quitaremos los valores NA, porque nos gustaría poder interpretar las frecuencias relativas de las personas físicamente activas versus las inactivas. Sin embargo, para que esto tenga sentido tendríamos que asumir que los valores “NA” están perdidos de manera “aleatoria,” significando que su presencia o ausencia no está relacionada con el verdadero valor de la variable para esa persona. Por ejemplo, si los participantes inactivos tuvieran mayor probabilidad de rehusarse a contestar la pregunta que los participantes activos, entonces eso sesgaría nuestra estimación de la frecuencia de la actividad física, lo que significa que nuestra estimación sería diferente del valor verdadero.
| PhysActive | AbsoluteFrequency | RelativeFrequency | Percentage |
|---|---|---|---|
| No | 2473 | 0.45 | 45 |
| Yes | 2972 | 0.55 | 55 |
La Tabla 3.2 nos deja ver que el 45.4 porciento de los individuos en la muestra NHANES dijo “No” y el 54.6 porciento dijo “Sí.”
3.2.2 Distribuciones acumuladas
La variable PhysActive que revisamos arriba sólo tenía dos valores posibles, pero frecuentemente queremos resumir datos que pueden tener más valores posibles. Cuando esos valores son cuantitativos, entonces una manera útil de resumirlos es a través de lo que llamamos una representación de frecuencias acumuladas: en lugar de preguntarnos cuántas observaciones toman un valor específico, nos preguntamos cuántas observaciones tienen un valor en específico o menor a ese valor.
Démosle un vistazo a otra variable en la base de datos NHANES, llamada SleepHrsNight que registra cuántas horas el participante reportó que duerme usualmente entre semana. Construyamos una tabla de frecuencias como la que hicimos arriba, después de quitar a las personas que tienen dato perdido en este pregunta. La Tabla 3.3 muestra una tabla de frecuencias creada como las de arriba, después de quitar a todas las personas que tuvieran datos perdidos para esta pregunta. Podemos comenzar a resumir los datos sólo con observar la tabla; por ejemplo, podemos ver que la mayoría de las personas reportan dormir entre 6 y 8 horas. Para ver esto de manera aún más clara, podemos graficar un histograma que nos muestre el número de casos que tuvieron cada uno de los valores; observa el panel izquierdo de la Figura 3.2. También podemos graficar las frecuencias relativas, a las cuales frecuentemente llamaremos densidades - observa el panel derecho de la Figura 3.2.
| SleepHrsNight | AbsoluteFrequency | RelativeFrequency | Percentage |
|---|---|---|---|
| 2 | 9 | 0.00 | 0.18 |
| 3 | 49 | 0.01 | 0.97 |
| 4 | 200 | 0.04 | 3.97 |
| 5 | 406 | 0.08 | 8.06 |
| 6 | 1172 | 0.23 | 23.28 |
| 7 | 1394 | 0.28 | 27.69 |
| 8 | 1405 | 0.28 | 27.90 |
| 9 | 271 | 0.05 | 5.38 |
| 10 | 97 | 0.02 | 1.93 |
| 11 | 15 | 0.00 | 0.30 |
| 12 | 17 | 0.00 | 0.34 |
Desde este momento podemos resumir los datos sólo al observar la tabla; por ejemplo, podemos ver que la mayoría de las personas reportaron dormir entre 6 y 8 horas. Grafiquemos los datos para ver esto de manera más clara. Para hacer esto podemos graficar un histograma que nos permite ver el número de casos que hay por cada uno de los valores; ve el panel izquierdo de la Figura 3.2. También podemos graficar las frecuencias relativas, a este tipo de gráfica nos referirimos frecuentemente como densidades - ve el panel derecho de la Figura 3.2.
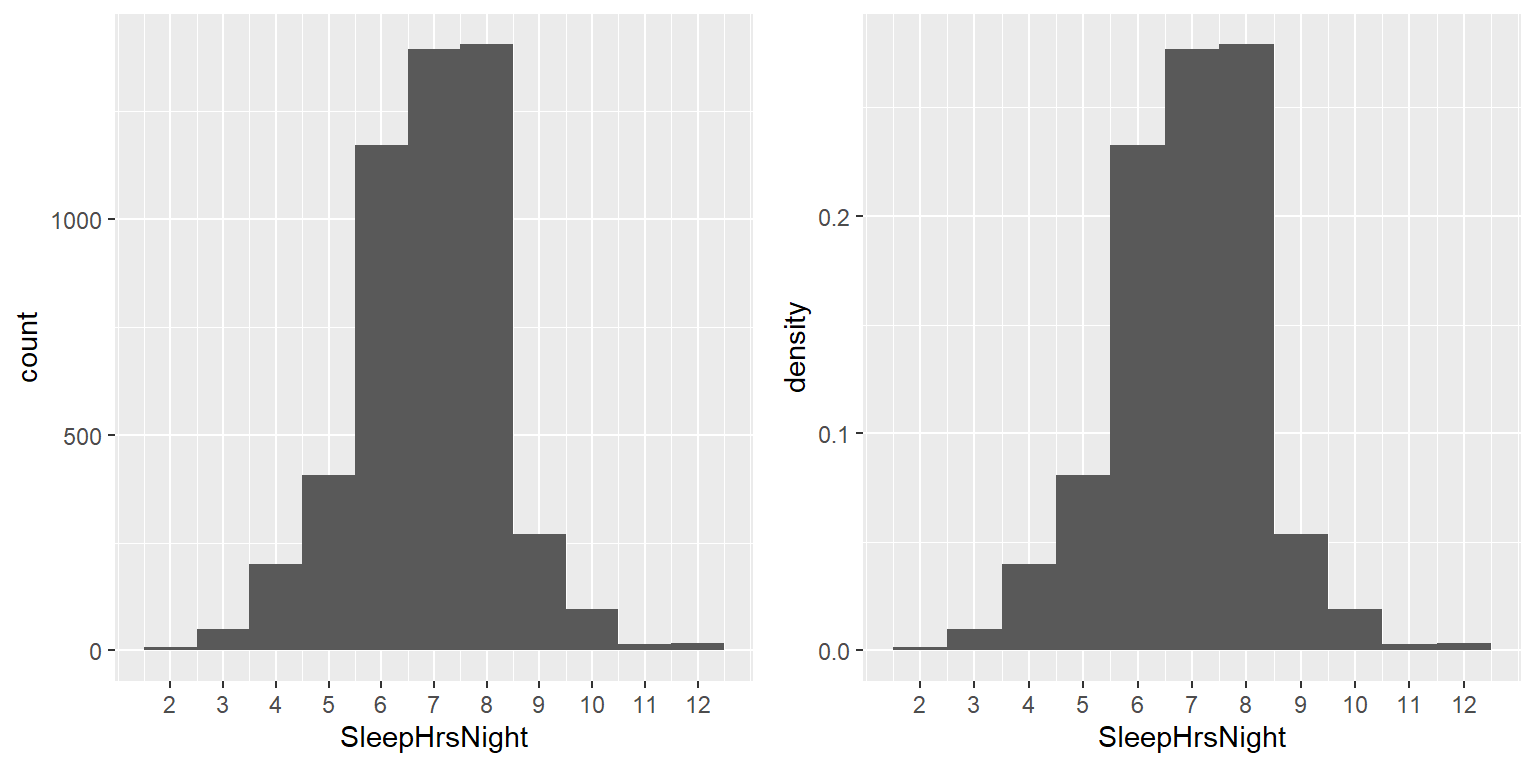
Figura 3.2: Histogramas que muestran el número (izquierda) y la proporción (derecha) de las personas que reportaron cada valor posible en la variable SleepHrsNight.
¿Qué pasa si quisiéramos saber cuántas personas reportaron dormir 5 horas o menos? Para encontrar esto, podemos calcular una distribución acumulada. Para calcular la frecuencia acumulada para un valor j, sumamos las frecuencias de todos los valores hasta j, incluyendo también la frecuencia del valor j:
\[ frecuencia\ acumulada_j = \sum_{i=1}^{j}{frecuencia\ absoluta_i} \]
| SleepHrsNight | AbsoluteFrequency | CumulativeFrequency |
|---|---|---|
| 2 | 9 | 9 |
| 3 | 49 | 58 |
| 4 | 200 | 258 |
| 5 | 406 | 664 |
| 6 | 1172 | 1836 |
| 7 | 1394 | 3230 |
| 8 | 1405 | 4635 |
| 9 | 271 | 4906 |
| 10 | 97 | 5003 |
| 11 | 15 | 5018 |
| 12 | 17 | 5035 |
Hagamos esto para nuestra variable de sueño, calculemos las frecuencias absolutas y acumuladas. En el panel izquierdo de la Figura 3.3 graficamos los datos para ver cómo se ven estas representaciones; los valores de frecuencias absolutas están graficados con líneas sólidas (continuas), y las frecuencias acumuladas están graficadas con líneas punteadas. Podemos ver que las frecuencias acumuladas van incrementándose monotónicamente – esto es, sólo pueden ir hacia arriba o mantenerse constantes, pero nunca pueden disminuir. De nuevo, usualmente encontramos las frecuencias relativas más útiles que las absolutas; esas están graficadas en el panel derecho de la Figura 3.3. De manera importante, la forma de la gráfica de frecuencias relativas es exactamente la misma que la de la gráfica de frecuencias absolutas – sólo el tamaño de los valores ha cambiado.
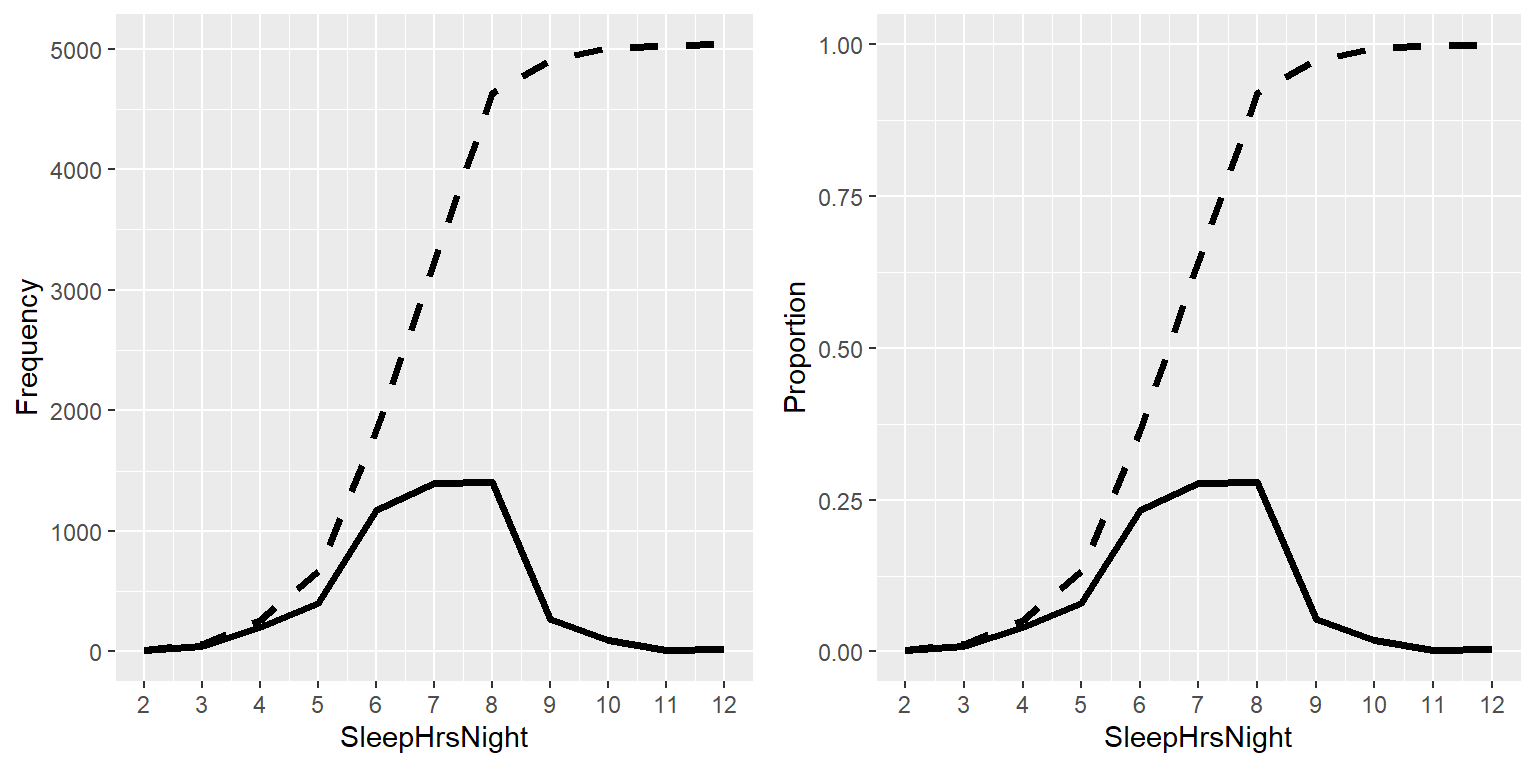
Figura 3.3: Gráfica con los valores relativos (líneas sólidas/continuas) y relativos acumulados (líneas punteadas) de las frecuencias (izquierda) y proporciones (derecha) de los posibles valores de SleepHrsNight.
3.2.3 Graficar histogramas
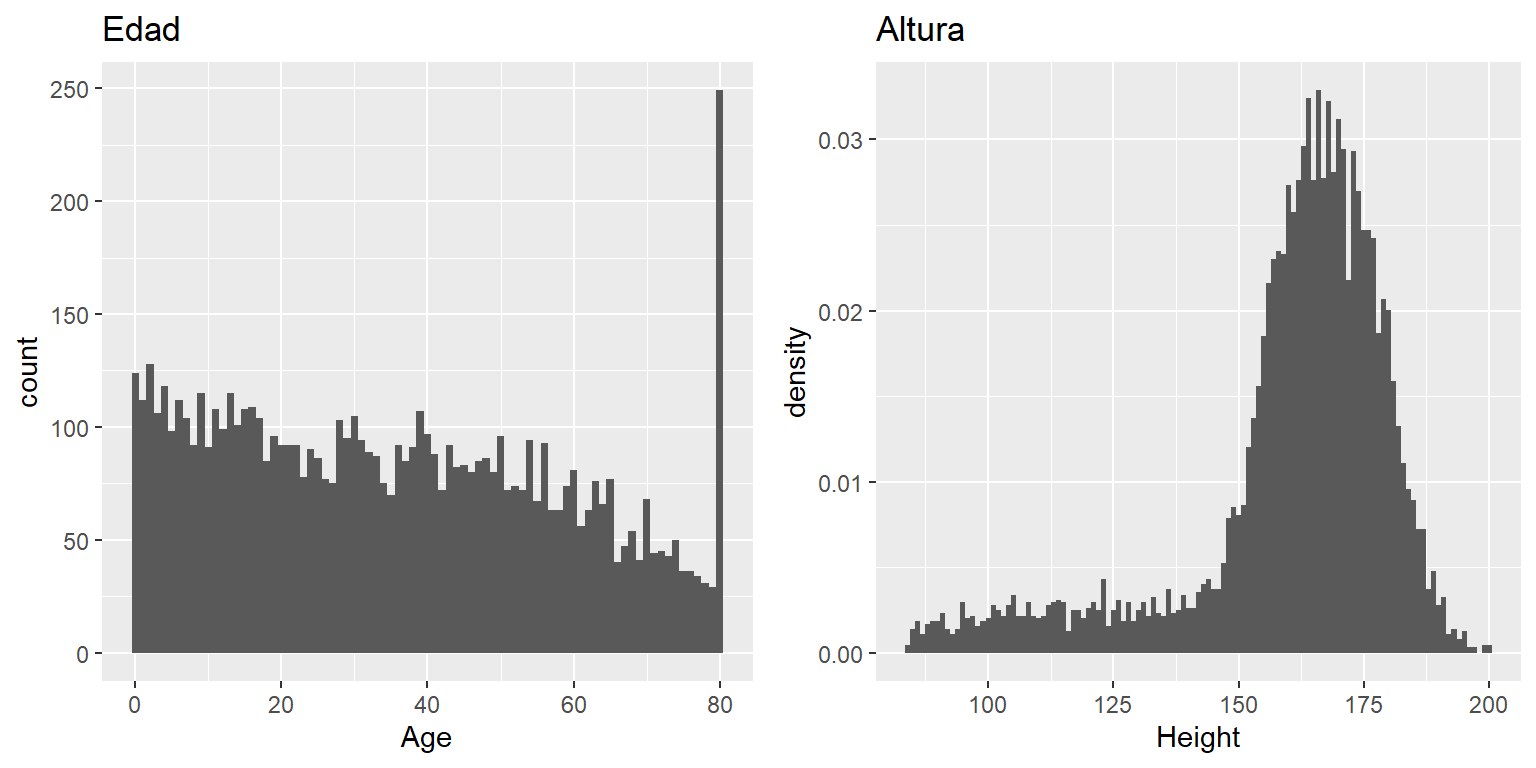
Figura 3.4: Histograma de las variables de Edad (izquierda) y Altura (derecha) en NHANES.
Las variables que hemos examinado arriba eran bastante simples, pudiendo tener sólo unos pocos valores posibles. Ahora veamos una variable más compleja: Edad. Primero, grafiquemos la variable Edad para todos las personas en la base de datos de NHANES (ve el panel izquierdo de la Figura 3.4). ¿Qué ves ahí? Primero, deberías notar que el número de personas en cada grupo de edad va disminuyendo con el tiempo. Esto tiene sentido porque la población fue muestreada aleatoriamente, y pasa que los fallecimientos a lo largo del tiempo lleva a que haya menos personas en los rangos de edad más avanzada. Segundo, probablemente notes un pico grande en la gráfica en la edad de 80 años. ¿Qué piensas que sea eso?
Si buscáramos la información acerca de la base de datos NHANES, veríamos la siguiente definición para la variable Edad: “Edad en años del participante al momento de su inclusión en la investigación. Nota: Participantes de 80 años o más fueron registrados como 80.” La razón para esto es que la muestra relativamente pequeña de individuos con edades muy altas podría hacer potencialmente más fácil el poder identificar a las personas específicas en la base de datos si uno conoce su edad exacta; los investigadores generalmente prometen a sus participantes el mantener su identidad de manera confidencial, y esta es una de las cosas que se pueden hacer para ayudar a proteger a los participantes. Esto subraya el hecho de que siempre es importante conocer de dónde proviene la información que tenemos y conocer cómo ha sido procesada; de otra manera podríamos interpretar los datos de manera inapropiada, pensando que las personas de 80 años de edad hayan sido sobrerrepresentadas en la muestra de alguna manera.
Veamos otra variable más compleja en la base de datos NHANES: Altura. El histograma de los valores de altura está graficada en el panel derecho de la Figura 3.4. La primera cosa que deberías notar acerca de esta distribución es que la mayoría de su densidad está centrada alrededor de 170 cm, pero su distribución tiene una “cola” a la izquierda; hay un número pequeño de individuos con alturas más pequeñas. ¿Qué piensas que está sucediendo ahí?
Habrás intuido que las alturas pequeñas vienen de niños y niñas en la base de datos. Una manera de examinar esto es graficando un histograma con los colores separados para niños y adultos (panel izquierdo de la Figura 3.5). Esto muestra que todas las alturas más bajas en efecto son de niños y niñas en la muestra. Realicemos una nueva versión de NHANES que sólo incluya adultos, y después grafiquemos el histograma sólo para ellos (panel derecho de la Figura 3.5). En esa gráfica la distribución se mira mucho más simétrica. Como veremos después, este es un buen ejemplo de una distribución normal (o Gaussiana).
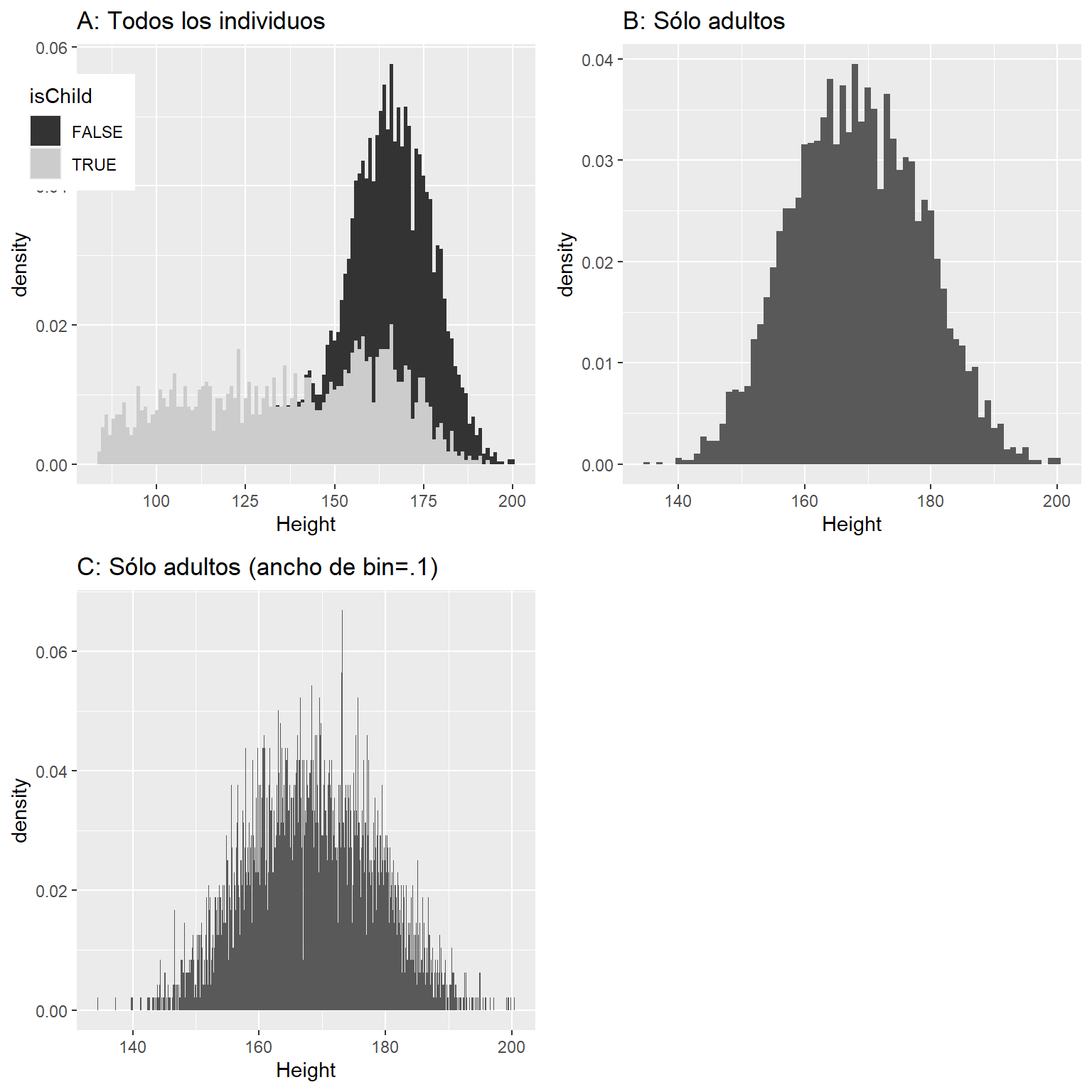
Figura 3.5: Histograma de las alturas en NHANES. A: Valores graficados separando niños y niñas (gris) y adultos (negro). B: Valores sólo para adultos. C: Igual que B, pero con ancho de bins = 0.1
3.2.4 Bins de un histograma
En nuestro ejemplo anterior con la variable de sueño, los datos fueron reportados en números enteros, y nosotros simplemente contamos el número de personas que reportaron cada valor posible. Sin embargo, si observas algunos de los valores en la variable de Altura en NHANES (como se observa en la Tabla 3.5), verás que fueron medidos en centímetros hasta la primera posición decimal.
| Height |
|---|
| 169.6 |
| 169.8 |
| 167.5 |
| 155.2 |
| 173.8 |
| 174.5 |
El panel C de la Figura 3.5 muestra un histograma que cuenta la densidad de cada posible valor redondeado al primer valor decimal. El histograma se ve muy irregular, esto es por la variabilidad en los valores decimales específicos. Por ejemplo, el valor 173.2 ocurre 32 veces, mientras que el valor 173.3 ocurre sólo 15 veces. Probablemente no vamos a pensar que existe una diferencia tan grande entre la prevalencia de estas dos alturas; lo más probable es que esto se deba a variabilidad aleatoria en nuestra muestra de personas.
En general, cuando creamos un histograma de datos que son continuos o donde se tienen muchos valores posibles, crearemos bins con los valores para que en lugar de contar y graficar la frecuencia de cada valor específico, contaremos y graficaremos la frecuencia de valores que caen dentro de rangos específicos. Esa es la razón por la cual se ve menos irregular la gráfica arriba en el Panel B de la Figura 3.5; en este panel establecimos el ancho de los bins en 1, lo que significa que el histograma es calculado al combinar valores dentro de los bins con un ancho de uno; por lo que los valores 1.3, 1.5, 1.6 contarían en la frecuencia de un mismo bin, el cual se extendería desde valores iguales a uno hasta valores menores a 2.
Puedes notar que una vez que el tamaño de bin ha sido seleccionado, entonces el número de bins es determinado por los datos:
\[ número\, de\, bins = \frac{rango\, de\, valores}{ancho\, de\, bin} \]
No existe una regla rígida u objetiva para escoger el ancho de bins óptimo. Ocasionalmente será obvio (como cuando sólo existen unos pocos valores posibles), pero en muchos casos requerirá ensayo y error. Existen métodos para tratar de encontrar un tamaño de bin óptimo de manera automática, como el método Freedman-Diaconis que usaremos en algunos ejemplos más adelante.
3.3 Representaciones idealizadas de distribuciones
Las bases de datos son como copos de nieve, en que cada una es diferente, a pesar de ello existen patrones que frecuentemente se observan en diferentes tipos de datos. Esto nos permite usar representaciones idealizadas de los datos para resumirlos aún más. Tomemos las alturas de los adultos graficadas en 3.5, y grafiquémoslas al lado de una variable muy diferente: ritmo cardíaco (latidos por minuto), también medido en NHANES (véase la Figura 3.6).
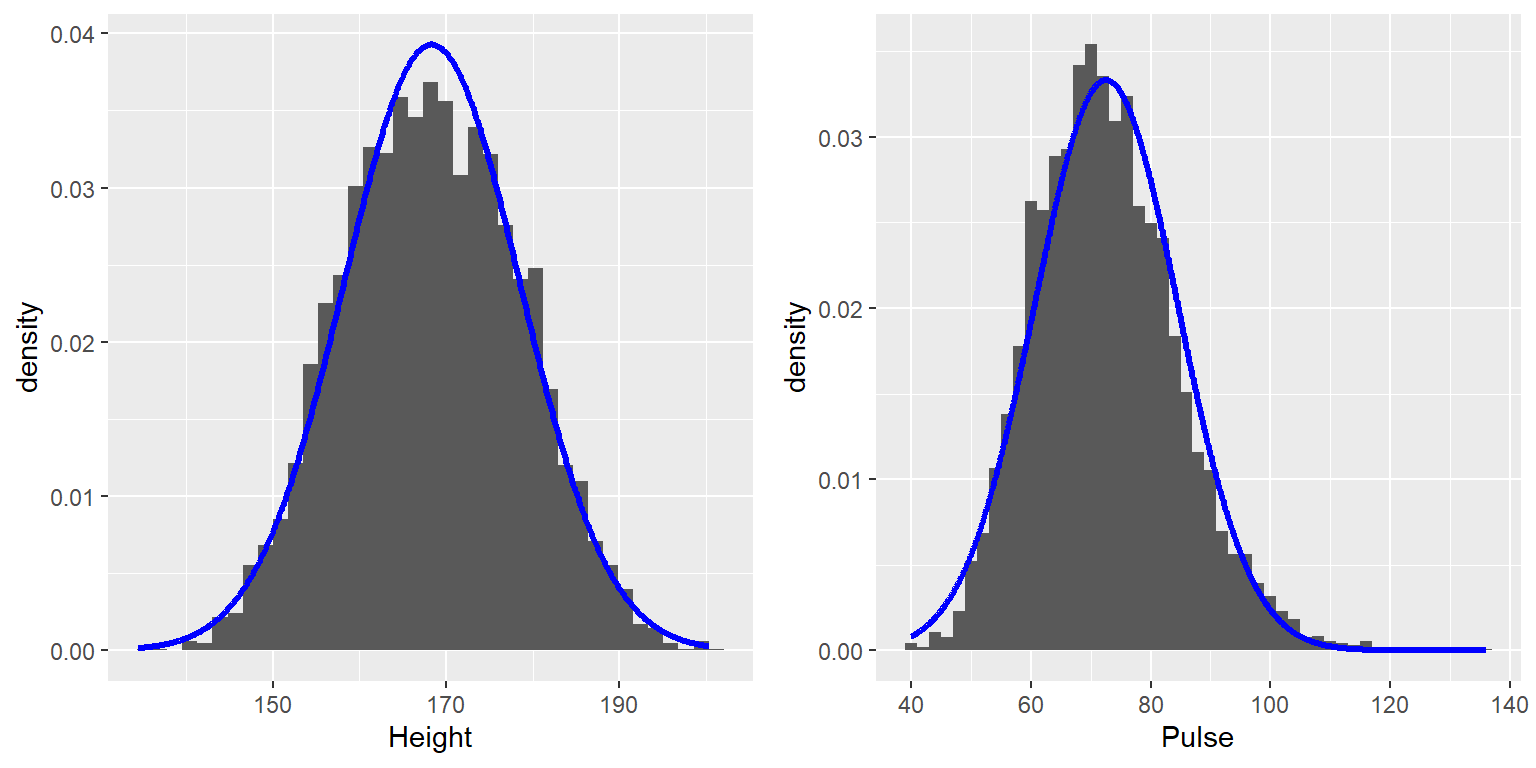
Figura 3.6: Histogramas de la altura (izquierda) y pulso (derecha) en la base de datos NHANES, con la distribución normal sobrepuesta en cada conjunto de datos.
Mientras que estas gráficas ciertamente no se ven exactamente iguales, ambas tienen la característica general de ser relativamente simétricas alrededor de un pico redondeado en el medio. De hecho, esta forma es una de las formas de distribuciones comúnmente observadas cuando recolectamos datos, a esta forma se le llama distribución normal (o Gaussiana). Esta distribución es definida en términos de dos valores (los cuales llamamos parámetros de la distribución): la localización del pico central (que llamamos media) y el ancho de la distribución (que es descrita en términos de un parámetro llamado desviación estándar). La Figura 3.6 muestra la distribución normal apropiada graficada encima de cada uno de los histogramas. Puedes ver que aunque las curvas no se ajustan exactamente a los datos, hacen un muy buen trabajo de caracterizar la distribución – ¡con sólo dos números!
Como veremos más tarde cuando discutamos el teorema del límite central, existe una razón matemática profunda por la cual muchas variables en el mundo exhiben la forma de una distribución normal.
3.3.1 Asimetría (sesgo)
Los ejemplos en la Figura 3.6 siguen una distribución normal relativamente bien, pero en muchos casos los datos se desviarán de una manera sistemática de la distribución normal. Una manera en la que los datos se pueden desviar es cuando son asimétricos (o sesgados), cuando una cola de la distribución es más densa que la otra. Nos referimos a esto como “asimetría” (o sesgo, “skewness” en inglés). La asimetría comúnmente sucede cuando la medida está restringida a ser no-negativa, como cuando estamos contando cosas o midiendo lapsos de tiempo (y por lo tanto la variable no puede tomar valores negativos).
Un ejemplo de asimetría relativamente moderada se puede ver en el promedio de tiempos de espera en las líneas de seguridad aeropuertaria del Aeropuerto Internacional de San Francisco, graficado en el panel izquierdo de la Figura 3.7. Puedes observar que mientras la mayoría de los tiempos son menores a 20 minutos, hay un número de casos donde pueden ser mucho mayores, ¡sobre los 60 minutos! Este es un ejemplo de una distribución “asimétrica a la derecha,” donde la cola derecha es más larga que la izquierda; este tipo de asimetría es común cuando observamos conteos o tiempos medidos, que no pueden ser menores a cero. Es menos común ver distribuciones “asimétricas a la izquierda,” pero pueden ocurrir, por ejemplo cuando vemos valores de fracciones que no pueden tomar valores mayores a uno.
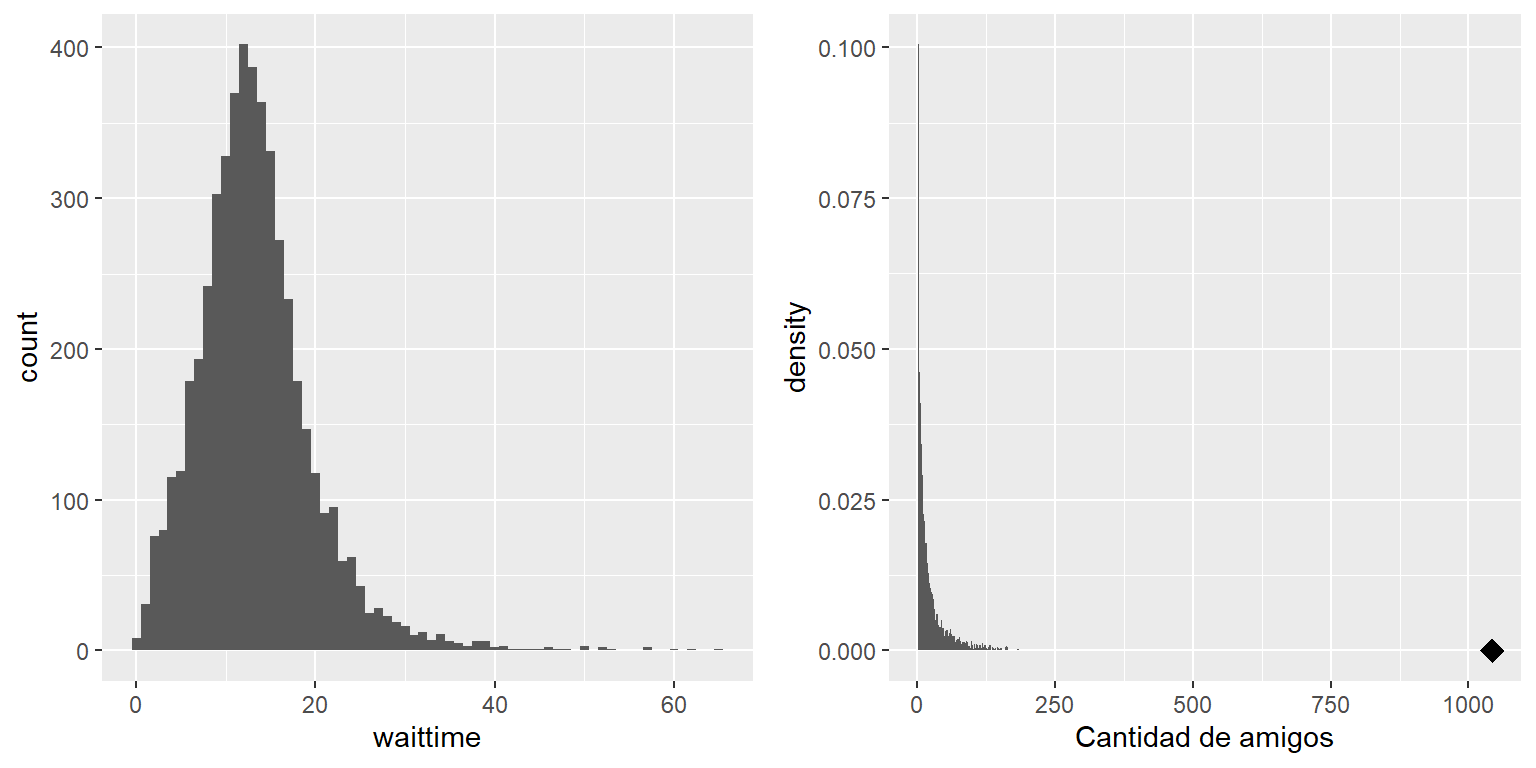
Figura 3.7: Ejemplos de distribuciones asimétricas a la derecha y con cola larga. Izquierda: Tiempo promedio de espera en seguridad en el SFO Terminal A (Enero-Octubre 2017), obtenidos de https://awt.cbp.gov/ . Derecha: Histograma del número de amigos en Facebook en 3,663 personas, obtenidos de la Stanford Large Network Database. La persona con el máximo número de amigos está indicada con un diamante.
3.3.2 Distribuciones con colas largas
Históricamente, la estadística se ha enfocado fuertemente en datos que están distribuidos de manera normal, pero existen muchos tipos de datos que no se parecen en nada a la distribución normal. En particular, muchas distribuciones en el mundo real tienen “cola larga,” esto significa que la cola derecha se extiende mucho más allá de los valores típicos de la distribución; esto es, son extremadamente asimétricas (o sesgadas). Uno de los tipos de datos más interesantes donde ocurren distribuciones con cola larga suceden del análisis de redes sociales (social networks). Para un ejemplo, veamos los datos sobre la cantidad de amigos en Facebook del Stanford Large Network Database y grafiquemos el histograma del número de amigos en una muestra de 3,663 personas en la base de datos (ve el panel derecho de la Figura 3.7). Como podemos ver, esta distribución tiene una cola derecha muy larga – la persona promedio tiene 24.09 amigos, ¡mientras que la persona con la mayor cantidad de amigos (marcada por el diamante) tiene 1043!
Distribuciones con cola larga han sido cada vez más reconocidas en el mundo real. En particular, muchas características de sistemas complejos son caracterizadas por estas distribuciones, desde la frecuencia de palabras en un texto, hasta el número de vuelos que llegan y salen de diferentes aeropuertos, como la conectividad de redes neuronales. Existen diferentes maneras en que las distribuciones de cola larga pueden suceder, pero una común sucede en casos del llamado “Efecto Mateo” de la Biblia Cristiana:
Porque al que tiene, le será dado, y tendrá más; y al que no tiene, aun lo que tiene le será quitado. - Mateo 25:29, Reina Valera 1960.
Esto frecuentemente es parafraseado como “los ricos se enriquecen más” (o en el refrán “Dinero llama dinero”). En estas situaciones, las ventajas se combinan o multiplican, de tal manera que aquellos con más amigos tienen acceso aún a más amigos nuevos, y aquellos con más dinero tienen la habilidad de hacer cosas que incrementen sus riquezas aún más.
Conforme el curso avance veremos varios ejemplos de distribuciones de cola larga, y deberemos mantener en mente que muchas de las herramientas en estadística pueden fallar cuando nos enfrentamos con datos con cola larga. Como Nassim Nicholas Taleb señala en su libro “The Black Swan,” estas distribuciones de cola larga jugaron un papel crítico en la crisis financiera de 2008, porque muchos de los modelos financieros usados por los traders (operadores de inversiones) asumieron que los sistemas financieros seguirían una distribución normal, que claramente no siguieron.
3.4 Objetivos de aprendizaje
Habiendo leído este capítulo, deberías ser capaz de:
- Calcular distribuciones de frecuencia absolutas, relativas, y acumuladas para un conjunto de datos.
- Generar una representación gráfica de una distribución de frecuencias.
- Describir la diferencia entre una distribución normal y una distribución con cola larga, y describir las situaciones que comúnmente dan lugar a cada tipo de distribución.
3.5 Lecturas sugeridas
- The Black Swan: The Impact of the Highly Improbable, por Nassim Nicholas Taleb.